



پرسپترون چند لایه: ستون فقرات شبکههای عصبی مصنوعی
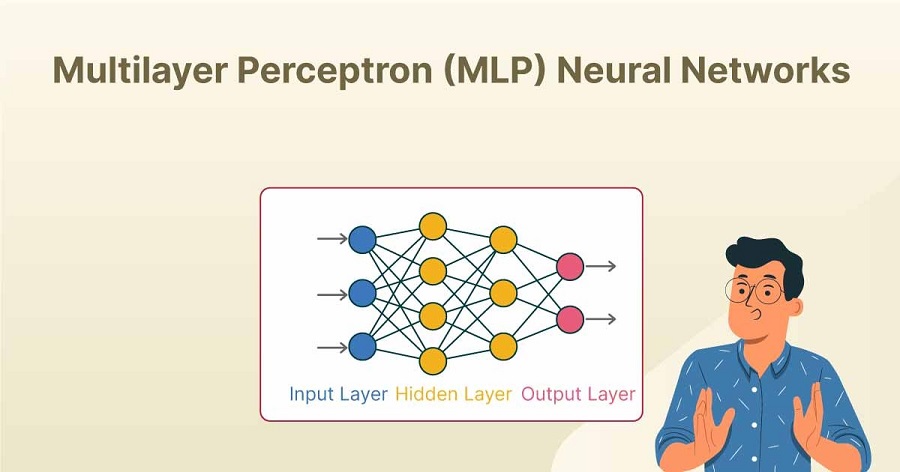
پرسپترون چند لایه (Multi-Layer Perceptron) یا (MLP) یکی از بنیادیترین و پرکاربردترین انواع شبکههای عصبی مصنوعی است. این مدل، با الهام از ساختار مغز انسان، قادر است الگوهای پیچیده را در دادهها شناسایی کرده و به مسائل مختلف یادگیری ماشین پاسخ دهد. در این مقاله، به بررسی عمیق پرسپترون چند لایه، اجزای تشکیلدهنده آن، نحوه عملکرد و کاربردهای گسترده آن خواهیم پرداخت.
آموزش یادگیری ماشین با کمترین قیمت
ساختار پرسپترون چند لایه
پرسپترون چند لایه از چندین لایه نورون تشکیل شده است که به صورت سلسلهوار به هم متصل هستند. این لایهها معمولاً به سه دسته تقسیم میشوند:
- لایه ورودی: این لایه، دادههای خام را دریافت کرده و آنها را به لایههای بعدی منتقل میکند. تعداد نورونهای این لایه برابر با تعداد ویژگیهای ورودی است.
- لایههای پنهان: بین لایه ورودی و خروجی قرار دارند و وظیفه استخراج ویژگیهای پیچیدهتر از دادهها را بر عهده دارند. تعداد لایههای پنهان و تعداد نورونها در هر لایه، بر اساس پیچیدگی مسئله قابل تنظیم است.
- لایه خروجی: خروجی نهایی شبکه را تولید میکند. تعداد نورونهای این لایه برابر با تعداد کلاسهای خروجی است.
مطلب پیشنهادی: برنامه نویسی شی گرا چیست؟
عملکرد پرسپترون چند لایه
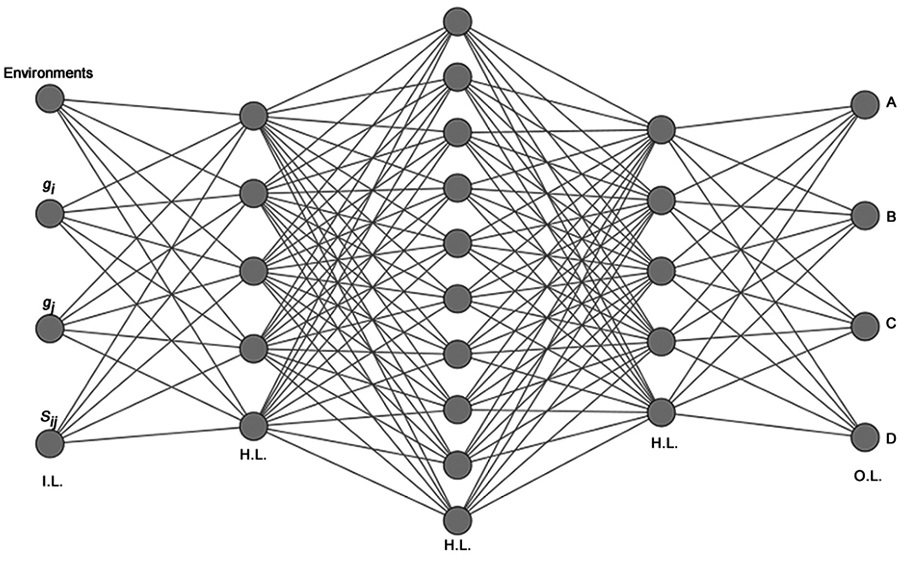
عملکرد پرسپترون چند لایه بر اساس انتقال سیگنالها بین نورونها و بهروزرسانی وزنهای اتصالات بین آنها است. هر نورون، مجموع وزندار ورودیهای خود را محاسبه کرده و سپس با استفاده از یک تابع فعالسازی، خروجی را تولید میکند. توابع فعالسازی مختلفی مانند سیگموئید، تانح و ReLU برای این منظور استفاده میشوند.
انتشار پیشرو (Forward Propagation): در این مرحله، سیگنال ورودی از لایه ورودی به لایههای بعدی منتقل شده و در نهایت به لایه خروجی میرسد. در هر لایه، خروجی هر نورون محاسبه شده و به عنوان ورودی برای نورونهای لایه بعدی استفاده میشود.
انتشار پسرو (Backpropagation): پس از محاسبه خطای بین خروجی شبکه و خروجی مورد انتظار، خطا به سمت عقب و لایههای قبلی منتشر میشود. در این مرحله، وزنهای اتصالات به گونهای بهروزرسانی میشوند که خطای شبکه کاهش یابد. این فرآیند به صورت تکراری انجام میشود تا زمانی که شبکه به دقت مورد نظر برسد.
مطلب پیشنهادی: ضریب هوشی نرمال چیست؟
یادگیری در پرسپترون چند لایه
پرسپترون چند لایه معمولاً با استفاده از طراحی الگوریتم یادگیری نظارتشده مانند گرادیان نزولی تصادفی (Stochastic Gradient Descent) آموزش داده میشود. در این روش، شبکه با ارائه نمونههای آموزشی و مقایسه خروجی شبکه با خروجی واقعی، وزنهای خود را بهروزرسانی میکند.
کاربردهای پرسپترون چند لایه
پرسپترون چند لایه در طیف وسیعی از مسائل یادگیری ماشین کاربرد دارد، از جمله:
- طبقهبندی: تشخیص دستنوشته، تشخیص چهره، تشخیص اسپم
- رگرسیون: پیشبینی قیمت مسکن، پیشبینی فروش
- پردازش زبان طبیعی: ترجمه ماشینی، تحلیل احساسات
- بینایی کامپیوتری: تشخیص اشیاء، ردیابی حرکت
مطلب پیشنهادی: صف در ساختمان داده چیست؟
مزایا و معایب پرسپترون چند لایه
مزایا:
- انعطافپذیری: توانایی یادگیری الگوهای پیچیده و غیرخطی
- عمومیت: کاربرد در طیف وسیعی از مسائل
- قابلیت یادگیری عمیق: با افزایش تعداد لایهها، شبکه میتواند ویژگیهای انتزاعیتری را استخراج کند.
معایب:
- زمان آموزش طولانی: برای شبکههای بزرگ و دادههای حجیم، آموزش میتواند زمانبر باشد.
- خطای بیشبرازسازی: اگر شبکه بیش از حد پیچیده باشد، ممکن است دادههای آموزشی را حفظ کند اما در مورد دادههای جدید عملکرد خوبی نداشته باشد.
- انتخاب تعداد لایهها و نورونها: تعیین تعداد مناسب لایهها و نورونها یک چالش است و نیاز به تنظیم دقیق دارد.
روشهای مختلف فعالسازی و اهمیت آنها در پرسپترون چند لایه
در بخش پیشین، به طور کلی به عملکرد پرسپترون چند لایه و نقش توابع فعالسازی در آن اشاره شد. در این بخش، به بررسی دقیقتر انواع توابع فعالسازی و اهمیت هر یک خواهیم پرداخت.
توابع فعالسازی، نقش کلیدی در تعیین خروجی یک نورون ایفا میکنند. این توابع، مجموع وزندار ورودیهای یک نورون را دریافت کرده و آن را به یک مقدار خروجی در بازه مشخصی نگاشت میکنند. انتخاب تابع فعالسازی مناسب، تأثیر بسزایی در عملکرد کلی شبکه عصبی بازگشتی دارد.
انواع توابع فعالسازی
1. تابع سیگموئید: (Sigmoid)
- یکی از قدیمیترین و شناختهشدهترین توابع فعالسازی است.
- خروجی این تابع بین 0 تا 1 قرار دارد.
- به دلیل مشتقپذیری، در الگوریتمهای یادگیری مبتنی بر گرادیان قابل استفاده است.
- مشکل: شیب تابع سیگموئید در مقادیر بزرگ یا کوچک ورودی به شدت کاهش مییابد (مشکل گرادیان ناپدیدشونده)، که باعث کند شدن فرایند یادگیری میشود.
2. تابع تانح: (Tanh)
- مشابه تابع سیگموئید است، اما خروجی آن بین -1 تا 1 قرار دارد.
- نسبت به تابع سیگموئید، مرکزیت بیشتری به صفر دارد و از نظر تئوری عملکرد بهتری در برخی از مسائل دارد.
- مشکل: همچنان از مشکل گرادیان ناپدیدشونده رنج میبرد.
3. تابع :ReLU (Rectified Linear Unit)
- یکی از پرکاربردترین توابع فعالسازی در شبکههای عصبی عمیق است.
- برای ورودیهای مثبت، خروجی برابر با خود ورودی و برای ورودیهای منفی، خروجی صفر است.
- مزایا: محاسبات ساده، گرادیان ثابت برای ورودیهای مثبت، کمک به حل مشکل گرادیان ناپدیدشونده.
- مشکل: نورونهایی که خروجی منفی داشته باشند، دیگر فعال نمیشوند (مشکل نورونهای مرده).
4. تابع :Leaky ReLU
- برای رفع مشکل نورونهای مرده در تابع ReLU، از تابع Leaky ReLU استفاده میشود.
- در این تابع، برای ورودیهای منفی، خروجی به صورت خطی با شیب کوچکی کاهش مییابد.
5. تابع :ELU (Exponential Linear Unit)
- ترکیبی از ویژگیهای تابع ReLU و تابع تانح است.
- برای ورودیهای مثبت، مانند ReLU عمل میکند و برای ورودیهای منفی، خروجی به صورت نمایی کاهش مییابد.
چرا انتخاب تابع فعالسازی مهم است؟
- سرعت همگرایی: توابع فعالسازی مختلف، سرعت همگرایی شبکه را تحت تأثیر قرار میدهند.
- مشکل گرادیان ناپدیدشونده: توابعی مانند ReLU و Leaky ReLU به طور موثر این مشکل را کاهش میدهند.
- نمایندگی ویژگیها: توابع مختلف، توانایی متفاوتی در نمایش ویژگیهای دادهها دارند.
- عمق شبکه: برای شبکههای عمیق، توابعی مانند ReLU معمولاً عملکرد بهتری دارند.
مطلب پیشنهادی: پردازش داده چیست؟
انتخاب تابع فعالسازی مناسب
انتخاب بهترین تابع فعالسازی به عوامل مختلفی از جمله:
- نوع داده: دادههای تصویری، متنی یا عددی
- مسئله مورد نظر: طبقهبندی، رگرسیون یا تولید داده
- الگوریتم بهینهسازی: در عمل، معمولاً با آزمایش توابع مختلف و انتخاب تابعی که بهترین عملکرد را برای مسئله مورد نظر دارد، به نتیجه مطلوب میرسیم.
توابع فعالسازی نقش بسیار مهمی در عملکرد شبکههای عصبی ایفا میکنند. انتخاب مناسب تابع فعالسازی، میتواند سرعت یادگیری، دقت مدل و توانایی تعمیمپذیری آن را بهبود بخشد. با درک عمیق از ویژگیهای هر تابع فعالسازی، میتوان مدلهای عصبی کارآمدتری را طراحی کرد.
تنظیم ابرپارامترها و روشهای جلوگیری از بیشبرازسازی در پرسپترون چند لایه
در پرسپترون چند لایه، علاوه بر وزنها و بایاسهای نورونها که در طی فرایند یادگیری بهروزرسانی میشوند، پارامترهای دیگری نیز وجود دارند که توسط طراح شبکه تعیین میشوند و به آنها ابرپارامتر (Hyperparameter) گفته میشود. تنظیم مناسب ابرپارامترها برای عملکرد مطلوب شبکه بسیار مهم است. برخی از ابرپارامترهای مهم عبارتند از:
- نرخ یادگیری : (Learning Rate) تعیین میکند که وزنها در هر مرحله از یادگیری چقدر بهروزرسانی شوند. نرخ یادگیری بالا ممکن است به نوسانات و عدم همگرایی منجر شود، در حالی که نرخ یادگیری پایین ممکن است روند یادگیری را کند کند.
- تعداد لایههای پنهان: تعداد لایههای پنهان بر پیچیدگی مدل تأثیر میگذارد. تعداد لایههای زیاد ممکن به بیشبرازسازی منجر شود، در حالی که تعداد لایههای کم ممکن است مدل را ناکافی کند.
- تعداد نورونها در هر لایه: تعداد نورونها در هر لایه نیز بر پیچیدگی مدل تأثیر میگذارد. تعداد نورونهای زیاد ممکن به بیشبرازسازی منجر شود، در حالی که تعداد نورونهای کم ممکن است مدل را ناکافی کند.
- تابع هزینه : (Loss Function) تابع هزینه، میزان خطای مدل را اندازهگیری میکند. انتخاب تابع هزینه مناسب برای مسئله مورد نظر مهم است.
- الگوریتم بهینهسازی: الگوریتم بهینهسازی روش بهروزرسانی وزنها را تعیین میکند. الگوریتمهای مختلفی مانند گرادیان نزولی تصادفی، آدام و RMSprop وجود دارد.
مطلب پیشنهادی: کلاس در جاوا چیست؟
روشهای جلوگیری از بیشبرازسازی
بیشبرازسازی (Overfitting) زمانی رخ میدهد که مدل بیش از حد به دادههای آموزشی تطبیق پیدا کند و در نتیجه در پیشبینی دادههای جدید عملکرد ضعیفی داشته باشد. برای جلوگیری از بیشبرازسازی، میتوان از روشهای زیر استفاده کرد:
- تنظیم وزن : (Regularization) با اضافه کردن یک جریمه به تابع هزینه، از رشد بیش از حد وزنها جلوگیری میشود. روشهای تنظیم وزن شامل L1 و L2 regularization هستند.
- دراپآوت : (Dropout) در هر مرحله از آموزش، تعدادی از نورونها به طور تصادفی غیرفعال میشوند. این روش باعث میشود مدل به ویژگیهای مختلف دادهها وابسته نشود.
- اعتبارسنجی متقاطع : (Cross-Validation) دادهها به چندین قسمت تقسیم میشوند و مدل بر روی قسمتهای مختلف آموزش و ارزیابی میشود. این روش کمک میکند تا عملکرد مدل بر روی دادههای جدید بهتر ارزیابی شود.
- افزایش حجم دادهها: افزایش حجم دادههای آموزشی میتواند به کاهش بیشبرازسازی کمک کند.
- کاهش پیچیدگی مدل: کاهش تعداد لایهها یا نورونها میتواند به سادهسازی مدل و کاهش بیشبرازسازی کمک کند.
تنظیم مناسب ابرپارامترها و استفاده از روشهای جلوگیری از بیشبرازسازی، دو عامل کلیدی در بهبود عملکرد پرسپترون چند لایه هستند. با آزمایش و تنظیم دقیق این پارامترها، میتوان مدلهای قوی و قابل تعمیمپذیری ایجاد کرد.
نتیجهگیری
پرسپترون چند لایه، به عنوان یکی از پایههای اصلی یادگیری عمیق، توانایی مدلسازی پیچیدگیهای نهفته در دادهها را داراست. در این مقاله، به بررسی ساختار، عملکرد و کاربردهای متنوع این مدل پرداختیم. از طریق توابع فعالسازی مختلف، پرسپترونها قادرند الگوهای غیرخطی را شناسایی کرده و به مسائل پیچیده طبقهبندی و رگرسیون پاسخ دهند. با این حال، تنظیم دقیق ابرپارامترها و مقابله با مسائلی مانند بیشبرازسازی، از چالشهای مهم در طراحی و آموزش این مدلها محسوب میشود.
در مجموع، پرسپترون چند لایه ابزاری قدرتمند برای تحلیل دادهها و استخراج اطلاعات مفید است. با پیشرفتهای اخیر در سختافزار و آموزش نرمافزار، شاهد کاربرد گسترده این مدل در حوزههای مختلفی مانند پردازش تصویر، پردازش زبان طبیعی و بینایی کامپیوتری هستیم. با این حال، همچنان تحقیقات بسیاری برای بهبود عملکرد و توسعه مدلهای پرسپترونی در حال انجام است. در آینده، میتوان انتظار داشت که پرسپترون چند لایه نقش محوری در توسعه و آموزش هوش مصنوعی و حل چالشهای پیچیدهتر داشته باشد.



.svg)