



آموزش پیمایش درخت در ساختمان داده
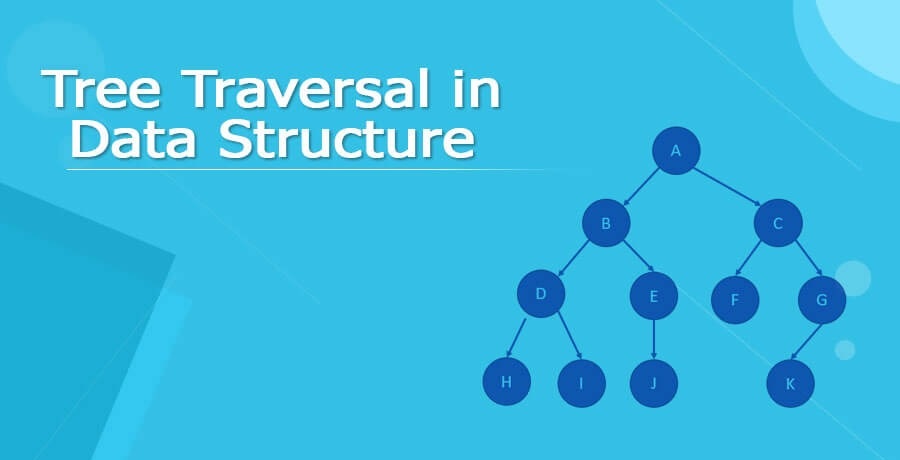
در دنیای امروز، علوم کامپیوتر و مهندسی نرمافزار به طور فزایندهای وابسته به ساختارهای دادهای پیچیده هستند. یکی از مهمترین این ساختارها، درختها هستند که به دلیل ویژگیهای خاص خود، در بسیاری از زمینهها از جمله مدیریت داده، پردازش زبان طبیعی و طراحی الگوریتم های جستجو کاربرد دارند. درختها بهعنوان یک ساختار دادهای غیرخطی، قادرند به طور مؤثری دادهها را سازماندهی و ذخیره نمایند و این قابلیت آنها را به ابزاری کارآمد برای حل مسائل مختلف تبدیل کرده است.
پیمایش درخت یکی از مفاهیم کلیدی در کار با ساختمان داده است که به ما اجازه میدهد دادهها را بهصورت مؤثر جستجو، درج و حذف نماییم. با درک عمیقتری از روشهای پیمایش درخت، میتوانیم روشهای بهتری برای حل مسائل پیچیده پیدا کنیم و به بهینهسازی الگوریتمها و ساختارهای دادهای بپردازیم.
آموزش پاور بی آی با بهترین هزینه و کیفیت
مراحل یادگیری پیمایش درخت در ساختمان داده
برای یادگیری پیمایش درخت در ساختمان داده، باید چندین مفهوم و تکنیک کلیدی را در نظر گرفت:
- آشنایی با ساختار درخت: ابتدا باید با ساختار درخت و انواع آن، از جمله درخت باینری آشنا شوید. درک نحوهی ذخیرهسازی و ارتباطات گرهها در یادگیری پیمایش درخت اهمیت دارد.
- آشنایی با انواع پیمایش:
- پیمایش پیشوندی (Pre-order Traversal)
در این روش، ابتدا گره جاری، سپس زیر درخت چپ و سپس زیر درخت راست بازدید میشوند.
- پیمایش میانوندی (In-order Traversal)
در این روش، ابتدا زیر درخت چپ، سپس گره جاری و سپس زیر درخت راست بازدید میشوند. این روش بهویژه برای درختهای جستجوی باینری اهمیت دارد.
- پیمایش پسوندی (Post-order Traversal)
در این روش، ابتدا زیر درخت چپ، سپس زیر درخت راست و سپس گره جاری بازدید میشوند.
- پیمایش سطح به سطح (Level-order Traversal)
در این روش، گرهها به ترتیب سطحی که در آن قرار دارند، بازدید میشوند.
پیادهسازی پیمایش: باید بتوانید هر یک از این روشهای پیمایش را با استفاده از روشهای بازگشتی و غیربازگشتی (استفاده از صف) پیادهسازی کنید.
- یادگیری استفاده از درختها: درک اینکه چگونه میتوان از درختها و الگوریتمهای پیمایش آنها در مسائل واقعی، مثل جستجو در پایگاههای داده، تجزیه و تحلیل دادهها و برنامهنویسی گرافیکی استفاده کرد.
مطلب پیشنهادی: رغبت سنجی چیست؟
آشنایی با ساختار درخت

پیمایش درخت یکی از ساختارهای دادهای مهم و پایهای در علوم کامپیوتر است. این ساختار، دادهها را بهصورت سلسلهمراتبی سازماندهی میکند. ساختار درخت میتواند برای نمایش سیستم فایلها، سازمانهای مدیریتی و یا ساختارهای دادهای پیچیده؛ مانند درختهای جستجو و باینری استفاده شود.
اجزای اصلی یک درخت:
- گره (Node)
هر عنصر در درخت را گره مینامند. هر گره میتواند شامل داده و همچنین اشارهگرهایی به دیگر گرهها (فرزندان) باشد.
- ریشه (Root)
گره بالایی و ابتدایی درخت که بدون والد است.
- برگ (Leaf)
گرهای که فرزند ندارند و در پایینترین سطح درخت قرار دارند.
- عمق (Depth)
عمق یک گره، فاصله آن تا ریشه درخت محسوب میشود.
- ارتفاع (Height)
ارتفاع یک درخت، حداکثر عمق گرههای آن است.
- فرزند (Child)
هر گرهای که مستقیماً به یک گره دیگر متصل است و زیرمجموعه آن محسوب میشود.
- والد (Parent)
هر گرهای که فرزند دارد، والد نامیده میشود.
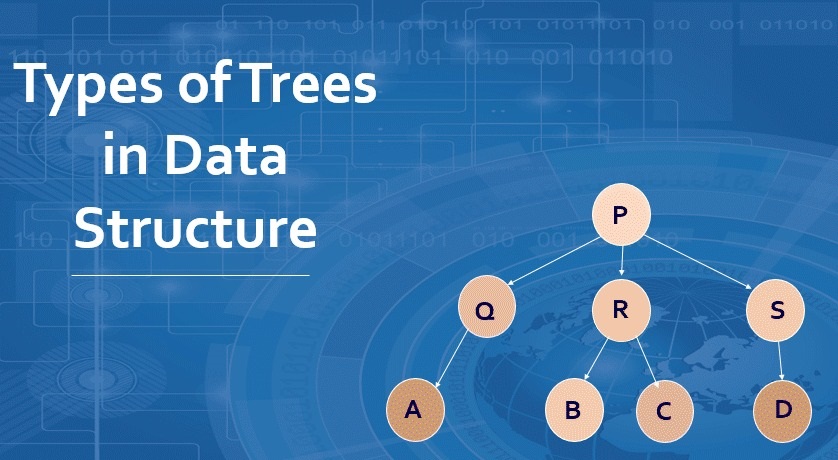
انواع درختها:
- درخت باینری (Binary Tree)
در این نوع درخت، هر گره میتواند حداکثر دو فرزند داشته باشد.
- درخت جستجوی باینری (Binary Search Tree)
نوع خاصی از درخت باینری که در آن گرهها بهگونهای سازماندهی میشوند که گرههای سمت چپ کمتر از والد و گرههای سمت راست بزرگتر از والد هستند.
مطلب پیشنهادی: مهارت های مورد نیاز برنامه نویسی
آشنایی با انواع پیمایشها
پیمایش درخت (Tree Traversal) به فرایند بازدید از همه گرههای یک درخت به ترتیب خاصی اشاره دارد. انواع مختلفی از پیمایش درخت وجود دارد که به طور عمده به دودسته اصلی تقسیم میشوند: پیمایش عمق اول و پیمایش عرض اول.
- پیمایش عمقاول (Depth-First Traversal)
این نوع پیمایش به ترتیب عمق درخت پرداخته و از گرههای عمیقتر به سمت بالاترین گرهها حرکت میکند. این پیمایش به سه روش اصلی انجام میشود:
- پیشوندی (Pre-order)
در این روش، گره والد قبل از فرزندانش بازدید میشود. ترتیب بازدید به شکل زیر است:
ـ بازدید از گره والد
ـ پیمایش زیر درخت چپ
ـ پیمایش زیر درخت راست
- میانوندی (In-order)
در این روش، ابتدا زیر درخت چپ سپس گره والد و بعد زیر درخت راست بازدید میشود:
ـ پیمایش زیر درخت چپ
ـ بازدید از گره والد
ـ پیمایش زیر درخت راست
- پسوندی (Post-order)
در این روش، ابتدا فرزندان (زیر درختها) و سپس گره والد بازدید میشوند:
ـ پیمایش زیر درخت چپ
ـ پیمایش زیر درخت راست
ـ بازدید از گره والد
- پیمایش عرضاول (Breadth-First Traversal)
این نوع پیمایش بهصورت سطح به سطح درخت را بازدید میکند. در واقع، ابتدا گرههای یک سطح بازدید میشوند و سپس به سطح بعدی میرود. این پیمایش معمولاً با استفاده از صف در ساختمان داده (Queue) انجام میشود. الگوریتم کلی بهصورت زیر است:
ـ ابتدا گره ریشه را به صف اضافه کنید.
ـ گره را از صف بردارید و بازدید کنید.
ـ اگر گره دارای فرزندان باشد، آنها را به صف اضافه کنید.
ـ این فرایند تا زمانی که صف خالی شود ادامه مییابد.
پیمایش درخت ابزارهای مهمی برای جستجو و سازماندهی دادهها در ساختارهای درختی به شمار میروند. انتخاب نوع پیمایش مناسب بستگی به نیاز خاص برنامه و نوع عملیات موردنظر دارد.
مطلب پیشنهادی: الگوریتم کروسکال چیست؟
یادگیری استفاده از درختها
درختها و الگوریتمهای پیمایش آنها ابزارهای پایهای در علوم کامپیوتر هستند که در مسائل مختلفی کاربرد دارند:
- جستجو در پایگاههای داده
درختهای جستجو مثل درختهای Binary به دلیل توانایی آنها در ذخیرهسازی و جستجوی سریع دادهها بسیار مورداستفاده قرار میگیرند.
- فشرده سازی اطلاعات
درختها برای مدیریت دادهها در دیسکها بهینهسازی شدهاند. آنها اجازه میدهند تا جستجوی باینری در فضای ذخیرهسازی که ممکن است بهصورت غیرخطی سازماندهی شده باشد، انجام شود. با استفاده از ویژگیهای درختهای Binary میتوان دادهها را به طور مؤثری فشرده کرد و زمان جستجو را کاهش داد.
- جستجوی سریع
با الگوریتمهای پیمایش مثل (Deep First Search) میتوان درختهای جستجو را سریعتر جستجو کرد.
- تجزیه و تحلیل دادهها
درختها در تجزیهوتحلیل دادهها و دستهبندی اطلاعات نیز کاربرد فراوانی دارند. درختهای تصمیم بهعنوان ابزاری برای مدلسازی و تحلیل دادهها استفاده میشوند. برای مثال، در درخت تصمیم، هر گره نشاندهنده یک سؤال یا تصمیم است و هر شعبه نشاندهنده نتیجه آن است. این درختها در یادگیری ماشین برای پیشبینی خروجیها استفاده میشوند.
- برنامهنویسی گرافیکی
درختها در برنامهنویسی گرافیکی نقش مهمی ایفا میکنند. با استفاده از الگوریتمهای پیمایش، میتوان بهراحتی همه عناصر قابلمشاهده در صحنه را تغییر داد.
بهطورکلی، درختها و الگوریتمهای پیمایش آنها ابزارهای قدرتمندی برای حل مشکلات مختلف در حوزههای گوناگون هستند. توانایی آنها در مدیریت دادهها بهصورت منظم و کارآمد، باعث میشود که در اکثر سیستمها و برنامهها از آنها استفاده شود. درک و تسلط بر ساختارهای درختی و الگوریتمهای مرتبط با آنها میتواند به بهبود عملکرد و کارایی سیستمهای نرمافزاری کمک کند.
مطلب پیشنهادی: پرسپترون چند لایه
مزایای استفاده از پیمایش درخت
درختها یکی از ساختارهای دادهای مهم در علوم کامپیوتر هستند که مزایای زیادی با خود به همراه دارند:
- ساختار سلسلهمراتبی: درختها برای نمایش دادههای با ساختار سلسلهمراتبی بسیار مناسب هستند. مثلاً میتوانند نمایشدهندة فایلها در سیستمعاملها باشند.
- افزایش و حذف عملگرها: درختها بهراحتی این امکان را فراهم میکنند که دادهها را اضافه یا حذف کنید.
- نظمدهی به دادهها: درختها به طور طبیعی دادهها را بهصورت مرتب نگه میدارند.
- پشتیبانی از عملیات پیچیده: درختها میتوانند وظایف پیچیدهتری مانند پیمایش پیشوندی، پسوندی و سطح به سطح را بهراحتی انجام دهند.
- استفاده در پایگاههای داده: درختها بهعنوان ساختار دادهای اصلی در برخی پایگاههای پردازش داده برای ذخیرهسازی و جستجوی دادهها استفاده میشوند.
- مدیریت حافظه: درختها میتوانند به بهینهسازی مصرف حافظه کمک کنند، بهخصوص زمانی که تعداد زیادی داده وجود داشته باشد و نیاز به جداسازی آنها باشد.
در نهایت، انتخاب ساختار داده مناسب بستگی به نیازهای خاص برنامه و نوع عملیاتی دارد که بر روی آنها انجام میشود، درختها به دلیل ویژگیها و مزایای خود در بسیاری از زمینهها محبوب هستند.
خطاها و چالشهای رایج در پیمایش درختها
در آموزش پیمایش درختها بهویژه در ساختمان داده، ممکن است با چالشها و خطاهای متعددی روبرو شویم:
- عدم درک ساختار درخت
درک نادرست از ساختار درخت و تفاوتهای بین انواع درختان میتواند منجر به مشکلات در پیادهسازی الگوریتمهای پیمایش شود.
- بکارگیری نادرست الگوریتمهای پیمایش
الگوریتمهای مختلف پیمایش (پیمایش پیشوندی، میانوندی، پسوندی و سطحی) هر کدام به یک منظور خاص طراحی شدهاند. انتخاب نادرست میتواند منجر به دستیابی به نتایج نادرست یا بهرهوری پایین شود.
- استفاده نادرست از پشته و صف
برای پیمایش درختها، بهویژه در روشهای بازگشتی و غیربازگشتی (با استفاده از پشته یا صف)، استفاده نادرست از داده میتواند به بروز خطا منجر شود.
- حجم داده و عمق درخت
درختهای عمیق ممکن است باعث بروز خطای سرریز پشته (stack overflow) در پیادهسازیهای بازگشتی شوند. این مسئله باید با مدیریت حجم داده و بهینهسازی کد حل شود.
- عدم توجه به شرایط پایه (Base Cases)
در پیادهسازی برخوردار از بازگشت (Recursion) ، عدم تعریف صحیح شرایط پایه میتواند منجر به حلقههای بیپایان یا نادرست کارکردن الگوریتم شود.
مطلب پیشنهادی: الگوریتم علف هرز
سخن پایانی
در پایان، میتوان گفت که آموزش پیمایش درخت در ساختمان دادهها یکی از موضوعات اساسی و کلیدی است که در درک و پیادهسازی الگوریتمها و ساختارهای دادهای مؤثر میباشد. درختها بهعنوان یکی از ساختارهای دادهای اصلی، در بسیاری از زمینهها از جمله بانک اطلاعاتی، سیستمهای فایل و الگوریتمهای جستجو و مرتبسازی کاربرد دارند. اهمیت یادگیری و تسلط بر روشهای پیمایش درخت، بهویژه در دنیای پرتحول فناوری اطلاعات امروز، غیرقابلانکار است؛ بنابراین، توصیه میشود که دانشجویان و علاقهمندان به آموزش برنامهنویسی و علم داده، وقت کافی را برای درک و تمرین این مباحث اختصاص دهند.



.svg)